
 business
business
The same system that lets developers back up Cosmos DB databases now also enables real-time analytics on live operational data, creating a blueprint for making it easier to integrate different cloud services.
The beauty of Cosmos DB, Microsoft’s low-latency, globally distributed database service, has always been how many different pieces it brings together. A mix different data models and database query APIs deliver the elastic scale of the cloud and NoSQL, while the rich query options of SQL database schemas and a selection of consistency models make creating a distributed system both flexible and straightforward.
Raghu Ramakrishnan, CTO for Azure Data: “We had a lightbulb moment…we have the infrastructure to connect the operational and analytics sides together.”
Image: Microsoft
Now you can also mix in analytics, processing operational, transactional data in real time, without either slowing down the operational databases or having to go through complex and tedious ETL processes to get a copy of the data to work with.
“You can have your cake and eat it, too,” Raghu Ramakrishnan, chief technology officer for Azure Data, told TechRepublic.
The new Azure Synapse Link for Cosmos DB was actually a handy side-effect of creating the change feed that’s used for the new continuous backup and point-in-time recovery feature (currently in preview).
Using a database in the cloud avoids many of the traditional reasons for taking backups: cloud services rarely suffer catastrophic failures so bad that they lose data, and if you take a backup to use if the cloud service isn’t available, you still need infrastructure on which to use that backup.
But you can still make a mistake, or roll out a change that turns out to be a bad idea, so the option to go up to 30 days back in time can be useful. Cosmos DB enables that by keeping a persistent record of every change to every container in your database, in the order that they happen. If you want to go back to a specific point in time, the system can use this change feed to work out what’s changed and undo it.
Developers can use the change feed to trigger actions for event-driven tools like Azure Functions, or to experiment with which of the different data properties is the most useful one to use for partitioning the data: set up two containers, each using a different data property as the key for the partitions, and replay the changes from the first container to the second and you can see which property works out best on live data without having to hold up the whole project while you decide. Some developers have been using the change feed as a replication mechanism for archiving older data — because everything goes through the change feed. It was the obvious way to create the backup feature.
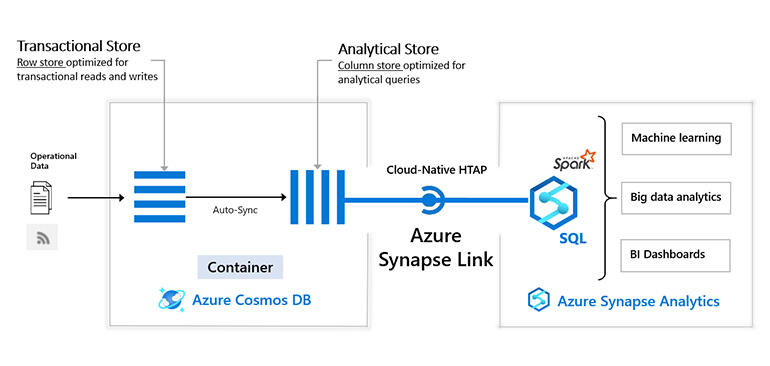
Azure Synapse Link creates a tight integration between Azure Cosmos DB and Azure Synapse Analytics.
Image: Microsoft
“Along the way, we had a lightbulb moment,” Ramakrishnan told TechRepublic. “We said ‘wait a minute, we have the infrastructure to connect the operational and analytics sides together’.”
“Every change is atomically, synchronously logged. We continually sniff the change feed and replay it while incrementally maintaining a columnar version of the data on the Synapse side.”
SEE: Hiring Kit: Application engineer (TechRepublic Premium)
Using the existing change feed means that bringing the data into Synapse doesn’t slow down Cosmos DB; that’s important because it’s widely used for ecommerce sites like Asos. When you look at the menu display in any Chipotle store around the world, it’s coming directly from Cosmos DB, the same way it does in their mobile app.
Ninety percent of the time, Ramakrishnan estimates, developers want to work with the data in Cosmos DB as transactional. “They don’t want to compromise on their transactional performance guarantees, but every so often, they want to issue these big honking queries.”
That means the data stored in Synapse can’t be structured in the same way it is in Cosmos DB, because data usage in the workloads varies so much.
“If you have inventory data in Cosmos DB you’re using it for inventory management and serving requests, but you also have your analytics hub and you want your analysis to reflect your inventory in real time,” Ramakrishnan said. “In Cosmos DB, I make a change to an inventory item, I look something up for a shopping cart. These are typically very focused retrievals and the latency demands are steep. In analytics, I say ‘give me the average standard deviation of this petabyte table’. They’re vastly different access patterns. Underneath, these classes of systems are doing very different things, and yet increasingly people want real-time operational analytics, and we want you to be able to do that without rolling your own ETL, which is a real pain.”
To enable that, the format in which data is stored with Azure Synapse is optimised for analytics performance. When you link the inventory tables to Synapse with Synapse Link, the service automatically builds a btree index, which is the way relational databases store sorted data efficiently. “It’s an auxiliary structure that lets you get sorted data. Say you have a table of employees and you want to do range queries on salary. If you have ordered access to that data, you can do it much more efficiently,” Ramakrishnan explained.
“But the beauty of it is, maintaining the auxiliary structure is on the database, not you. From your point of view, you gave the database a little hint about how you plan to use it and from there on, keeping up-to-date transactions, dealing with failure and all that nonsense — it’s up to the database. Effectively, you’re maintaining a columnar version of your data from Cosmos DB in a way that’s accessible to Synapse. So it’s a cross-service index, one of the first of its kind, and we take care of managing it completely transparently under the hood, in the background, in a way that doesn’t intrude on Cosmos DB.”
In fact, given the way cloud storage works, the virtual machines in which data for Cosmos DB or Synapse lives and the compute that powers them might be in the same physical rack anyway, Ramakrishnan points out. “All the distinctions are how we abstract and interpret it; we can easily make them transparent to the end user.”
Over the past couple of years, Microsoft has been progressively bringing together big data and data warehouses. “If you take big data, data lakes in Hadoop and Spark and that world, stored data and files have a range of engines. If you take data warehouses, stored data in managed data warehouses has SQL. These two worlds are converging,” Ramakrishnan said. “We give you a single sign-on to a secure workspace where you can use [Jupyter] notebooks, you can use Azure Data Studio, SQL Studio. You can use SQL or Spark on any of your data.” Microsoft will be adding more storage and query options to that list in future, he added.
“This is how we are bringing together the world of operational databases and analytic databases. And then we will do this for all other operational stores as well.”
Cloud services have become much more powerful, but connecting them together to do what you want is still too much work, Ramakrishnan admitted. Bringing together operational and analytical services is an attempt to help with that, as is the new Azure Purview service for handling compliance and governance across all your databases, storage and cloud services, which includes Cosmos DB, and the new managed Cassandra service, which can burst out to Cosmos DB.
“Customers are still having a lot of struggles doing things end-to-end, because literally anything you want to do involves stringing together many services. With the bar on privacy and security only going up, putting all these together, inside a vnet, in a compliant way, dealing with all the interop challenges of formats and metadata, is proving to be a big challenge. We believe that the future is going to be finding the right balance between having open standards, creating an open ecosystem — but at the same time in a Lego-like fashion, plug them into sockets, pre-integrate them, so the customer doesn’t have do the last mile.”
“These converged platforms are the key to providing enterprise-grade turnkey experience [in the cloud],” Ramakrishnan concluded.

Be your company’s Microsoft insider by reading these Windows and Office tips, tricks, and cheat sheets.
Delivered Mondays and Wednesdays
24World Media does not take any responsibility of the information you see on this page. The content this page contains is from independent third-party content provider. If you have any concerns regarding the content, please free to write us here: contact@24worldmedia.com






